

昨今のマテリアルズインフォマティクス(MI)においては、計算機シミュレーションによって生成された計算データが盛んに用いられています。一方で、計算データを”つかう”技術については数多く解説がなされていますが、計算データを”つくる”技術に関する解説はあまり多くないように思われます。この記事では計算データ生成において欠かせない技術であるハイスループット計算に焦点を当てて解説し、計算データを「どう使うか」だけでなく、「どう作るか」という視点からMIを捉え直してみます。
本稿は大きく、計算データセットおよびハイスループット計算の基礎を扱う前編と、実践的な内容を扱う後編に分けて解説します。前編では、計算データがMIにおいてなぜ重要なのかを確認したうえで、計算データセットの特徴を整理し、ハイスループット計算の基本的な考え方を説明します。
はじめに
マテリアルズインフォマティクス(MI)の実務においてしばしば直面する課題の一つに、学習データ不足があります。材料データは実世界での実験によって収集されるために取得コストが高く、また取得条件や環境に由来するバイアスやノイズがどうしても混入します。そのような中で大規模かつ高品質なデータセットを作成するのは容易ではないです。
このような状況に対して、密度汎関数理論 (DFT) や 分子動力学 (MD) といった計算化学的なシミュレーション手法によるデータ生成は有力な選択肢となり得ます(下図)。これらの手法は物質の性質をミクロな構成要素(原子・分子)に立ち返って記述する方法であるため、未知の物質に対する予測能力をある程度備えているという重要な特徴があります。
図1. 計算化学シミュレーションの概念図
シミュレーションは自動化が容易かつ並列に実行でき、実験と比べるとデータ生成効率に優れているため、これら計算化学を活用することで大規模データセットを効率的に作成可能です。以後、本稿中で計算ないしシミュレーションといった場合には基本的に原子・分子スケールの手法を想定するものとし、流体や連続体のようなマクロなシミュレーションについては(一部共通する点もあるものの)言及しないこととします。
現在公開されている材料データベースの中にもシミュレーション (特にDFT計算) を用いて作成されたものが数多く存在します。Materials Project はその代表例ともいえるデータベースで、60万件を越えるDFT計算データを公開しています。結晶構造を調べる際にお世話になったことがある方も多いのではないでしょうか?他にも分子系の計算データセットである QM9 や触媒表面計算データセットである OpenCatalyst など様々な材料系で計算データセットが公開されています。
計算データセットの特徴
ハイスループット計算について解説する前に、計算データセットがもつ特徴について簡単に触れておきます。MIで使用されるデータセットにはハイスループット実験で作成したものや文献値を収集したものなどいくつか種類がありますが、それらと比べて計算データセットには次のような特徴があるといえるでしょう。
- スケーラビリティが良い:先述のように、計算機シミュレーションは自動化しやすく並列実行が可能です。さらには機械学習によるシミュレーションそのものの高速化も可能なため、実験や文献収集と比べるとデータの生成効率の面で圧倒的に優位です。そのためデータセットを大規模化しやすく(スケーラビリティが良く)、現実的なコストで自前のデータセットを生成することができます。
- 原子・分子スケールの構造情報を扱える:DFTやMDを用いる大きな利点は原子・分子といった微視的な情報を扱える点です。これにより、実験からはアクセスしづらいナノスケールの構造に立脚した材料設計を行うことができます。また、計算過程で得られる電子状態や原子配置の情報を活用することで、他の方法では得られないようなきわめて精緻な化学特徴量を構築でき、特徴量設計の幅が大きく広がります。
- 化学空間のカバレッジが広い:機械学習は原理的に外挿を苦手とするため、MIにおいては化学空間をなるべく広範にサンプリングすることが望ましいです。この点においても計算は有利であり、装置や原料の入手しやすさといった現実的な制約に囚われることなく化学空間を探索することができます。
- 近似や単純化の影響が含まれる(短所):ここまで計算データセットの長所を述べてきましたが、一方で明確な短所もあります。それは、複雑な問題を現実的な時間で解くために数多の近似や単純化を行っており、しばしば現実との乖離を引き起こす点です。
以上はあくまで傾向ですので必ずしもこれに従うわけではありませんが、いずれにせよMIで利用されるデータセットには一長一短あるため、適切なデータセットの選択が重要になります。そして、目的に適うデータセットが利用できない場合には自分で作成する必要が出てきますが、その場合にはやはりデータ数を稼ぎやすい計算データセットが有力な選択肢となってきます。次はいよいよ本稿の主題である計算データを生み出す技術に焦点を当てていきます。
ハイスループット計算:計算データセットを生み出す技術
ハイスループット計算とは、ワークフロー制御システムや並列計算機を駆使して計算ワークフローを自動実行し、計算データを高効率に生成するような計算技術のことをいいます。計算ワークフローとは、例えば下の図のような、計算機シミュレーションにかかる一連の処理(入力ファイル生成、計算実行、結果の検証、データ蓄積)のことで、これを自動で高効率に実行することがハイスループット計算の目的です。
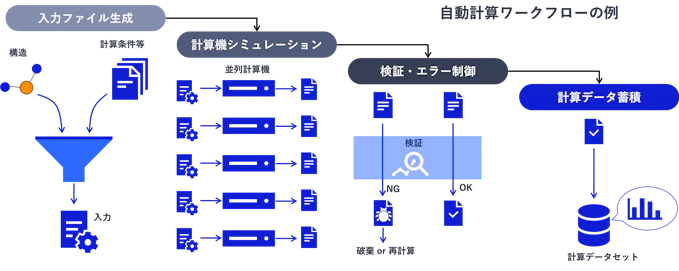
図2. 計算ワークフローの基本構造
ハイスループット計算においてはデータの生成効率が重要です。効率が高ければ高いほどデータセットの作成にかかるコストや時間が削減でき、その分だけ大規模なデータセットの生成が可能になります。この生成効率は具体的に計算システム中のどのような要素によって決まるのかをより詳しく見ていきましょう。最終的な生成効率には様々な要因が寄与しますが、中でも重要な要素として「(データあたりの)計算時間」と「歩留まり」が挙げられます。
$$ \text{データ生成効率} = \frac{\text{並列リソース数} \times \text{歩留まり}}{\text{計算時間}} $$
計算時間は文字通り計算データ1点を算出するまでに要する時間で、計算時間が短縮できると直接的にデータ生成効率の向上に寄与します。ちなみにこれはハイパフォーマンスコンピューティング(HPC)の文脈で語られる計算時間と同じですが、HPCの場合は大規模な計算課題を速く解くことを志向することが多いのに対し、ハイスループット計算では難しい計算課題を解くことよりも大量の(簡単な)計算タスクを効率よくこなすことを志向する、といった目的意識の違いはあります。
歩留まりは実行した計算の数に対する最終的に得られたデータ点数の割合で、平たく言うと計算の成功率です。計算は条件設定によっては時々失敗することがあります。最適化ループが収束しない、ノルムが保存しない、など現象は様々ですが、いずれにせよ失敗が多いとその分だけデータ生成効率は低下し、計算資源も無駄になります。そのためハイスループット計算においてはエラーに対する頑健性(ロバストさ)が常に要求され、計算実行中のエラー発生に対する計算制御機構の作りこみや異常終了した計算に対するリカバリーのしやすさが重要になります。
なぜ今ハイスループット計算が必要なのか?
ここまでハイスループット計算とは何なのか、その基本的な背景を解説してきましたが、その上で「自分でハイスループット計算を実行するモチベーションは何か?」という疑問を持たれるかもしれません。というのも、インターネット上には既に大規模な計算データセットおよび学習済みの基盤モデルが多数公開されているからです。
この問いに対する実務的な答えは、公開データセットと自分の課題設定が必ずしも一致するとは限らない、という点に集約されます。材料開発において扱われる材料系と物性の組合せは極めて多様であり、課題に整合したデータが公開データとして常に入手できるとは限りません。とりわけ物性値に関しては、公開データがエネルギーやトラジェクトリ等の汎用的な量に偏りがちで、目的とする性能指標を直接得ることができないケースが頻発します。したがって、ハイスループット計算を必要な物性・必要な条件で計画的にデータを補完する手段として持っておくことで、既存データに依存しない、より設計自由度の高いMIパイプラインを構築できます。
さらに一段踏み込むと、対象課題に整合した計算データを計画的に生成し、基盤モデルをドメイン適応させることで、モデルの性能を底上げすることができます。材料開発においては化学空間の全域探索というより、関心領域(組成系・相・温度圧力条件など)を明確に限定したうえで探索することが多いです。このとき重要なのは、汎用データから獲得した一般則を土台にしつつ、関心領域を高密度にサンプリングしたデータで再学習し、目的物性に関する精度/解像度を高めることです。すなわち、大規模データ・基盤モデルによる汎用的な知識の獲得と、課題特化データによるファインチューニングを組み合わせることで、汎化性を維持したまま注目領域での精度・頑健性を同時に引き上げる、という戦略が取れます。公開データセット・モデルが充実しているからこそ、ハイスループット計算を通じて自分の課題に特化したデータを追加し、モデルの最終性能を押し上げる戦略が有効になります。
前編では、計算データセットがMIの学習データ不足を補う有力な選択肢であり、DFTやMD計算によって効率よく生成できることを述べました。後編ではより実務的な側面に焦点をあて、ハイスループット計算を実践するための方法論について述べていきます。
参考文献
- Materials Project (https://next-gen.materialsproject.org/) 論文: A. Jain et al., "Commentary: The Materials Project: A materials genome approach to accelerating materials innovation", APL Mater. 1, 011002 (2013).
- QM9 (https://huggingface.co/datasets/jablonkagroup/qm9) 論文: R. Ramakrishnan et al., "Quantum chemistry structures and properties of 134 kilo molecules", Sci. Data 1, 140022 (2014).
- Open Catalyst 2020 (OC20) (https://opencatalystproject.org/) 論文: L. Chanussot et al., "The Open Catalyst 2020 (OC20) Dataset and Community Challenges", ACS Catal. 11, 6059–6072 (2021).















