

なぜバッチ最適化が重要なのか
ベイズ最適化は、高コストなブラックボックス問題に広く用いられています。すなわち、各試行が高価であり、探索空間が広く、最適解の位置を直接与える単純な数式が存在しない状況です。このような設定では、過去の観測データを利用して、次に試すべき点についてより情報に基づいた意思決定を行います。
最も単純な設定では、このプロセスは逐次的です。一つの候補が選択され、評価され、その結果に基づいてモデルが更新されてから、次の意思決定が行われます。この方法は、実験を一度に一つずつしか実行できない場合には有効です。
しかし、実際の多くのワークフローは純粋な逐次ではなく並列的です。例えば、実験室では同一ラウンドで複数のサンプルを準備できる場合があり、計算クラスタでは多数のジョブを同時に実行できます。また、顧客が一度のサイクルで複数の提案を受け取ることを望む場合もあります。バッチ型および並列型のベイズ最適化に関する研究は、このような逐次的意思決定規則と並列的実験現実との不整合を解消するために発展してきました。

図1. 単一点最適化とバッチ最適化の単純な比較。バッチ最適化における本質的な課題は、単に良い候補を選ぶことではなく、それらが一つの実験ラウンドとして意味を持つように選ぶことです。
ベイズ最適化の直感的理解
ベイズ最適化を説明する簡単な方法は、未知の地形を探索する研究者を想像することです。研究者は良好な領域を迅速に見つけたいと考えますが、各実験には高いコストがかかります。そのため、すべてを試すのではなく、既に得られたデータを用いて、成功確率が高い領域と不確実性が依然として大きい領域を推定します。
このため、多くの解説では、ベイズ最適化は二つの目標のバランスとして説明されます。すなわち、有望な領域への集中と、不確実な領域の探索です。本稿において重要なのは、このバランスの数学的詳細ではなく、その実務的帰結です。すなわち、限られた実験予算をより賢く使うための方法であるという点です。
バッチ選択によって何が変わるか
複数の実験を並列に実行できる場合、意思決定問題の構造は変化します。「次に最も良い一点は何か」ではなく、「次に最も良い点の集合は何か」を問うことになります。
この違いは重要です。なぜなら、バッチの価値は単純な個別スコアの総和ではないからです。例えば、上位5つの候補がすべて互いにわずかな差異しかない場合、そのバッチは多くのリソースを消費するにもかかわらず、新たな知見をほとんどもたらさない可能性があります。したがって、有用なバッチには同時に二つの要件が必要となります。すなわち、個別の有望性と、バッチ内での適度な多様性です。
この問題はバッチベイズ最適化の文献全体に共通して現れます。研究者は、同時に選択される点同士の相互作用を考慮するための様々な手法を提案しています。なぜなら、一度ある点が選択された場合、同一バッチ内の後続の点はその選択を無視すべきではないからです。
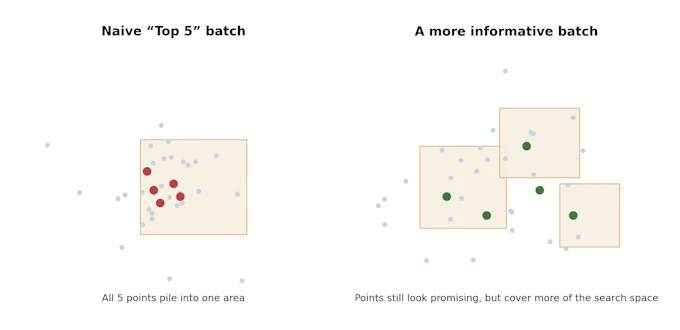
図2. バッチが単なる「上位5点」ではない理由です。左図はすべての点が局所領域に集中した非効率なバッチを示しています。右図はより情報量の高いバッチであり、有望性を保ちながら冗長性が低減されています。
バッチ戦略の主要な分類
文献には多様な手法が存在しますが、非専門家向けにはいくつかの大きな分類に整理することが有用です。
逐次シミュレーション型アプローチ
一つの代表的な考え方は、バッチを一点ずつ構築することです。最初の候補が選ばれた後、アルゴリズムはその候補に関する情報が既に得られているかのように一時的に仮定します。その仮定を用いて次の候補を選択し、この過程をバッチが満たされるまで繰り返します。Constant Liarはこの分類に属します。
多様性促進型アプローチ
別の分類では、より直接的に冗長性を低減しようとします。代表例として局所ペナルティ法があり、同一バッチ内の後続点が既に選択された点の近傍に集中することを抑制します。目的は多様性そのものではなく、有望性を維持しつつ探索領域を適切に分散させることです。
バッチ同時評価型アプローチ
より直接的ではあるものの、計算負荷が高くなる傾向のある方法として、バッチ全体を同時に評価するアプローチがあります。multi-point expected improvement(通常はq-EIと表記されます)はその代表例です。この手法は、真のバッチ最適化問題により忠実であるという利点がありますが、複数の研究において、バッチサイズが大きくなるにつれて最適化計算が困難になる可能性が指摘されています。
サンプリングベース並列アプローチ
もう一つの系統として、並列Thompson samplingのようなサンプリングベースの手法があります。これらの方法は概念的に比較的単純であり、並列実行と自然に整合します。特に、評価時間が不均一であったり、非同期実行が重要となる場合に有効です。
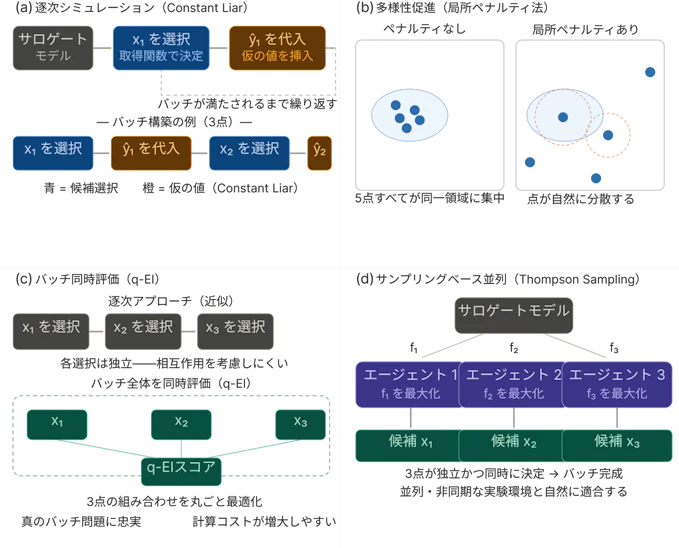
図3. バッチベイズ最適化における代表的な4戦略の概要
Constant Liar
Constant Liarは、逐次的にバッチを構築するための代表的な実用ヒューリスティックの一つです。その基本的な考え方は比較的単純です。最初の候補を選択した後、アルゴリズムは実際の結果を待ちません。その代わりに、その点に対して一時的な値を挿入し、それが既に観測されたかのようにモデルを更新した上で、次の候補を選択します。
この名称は、実際の観測結果ではない疑似的な観測値を用いることに由来します。すなわち、意図的に設定された仮の値です。並列クリギング最適化に関する初期研究において、この種のヒューリスティックは、厳密なバッチ計算の困難性を回避しつつ、同一バッチ内の先行選択を反映するための手法として導入されました。
このように考えると、Constant Liarは非常に実務的な意味を持ちます。すなわち、逐次的な意思決定ロジックをバッチ環境に適用可能にするための、構造化された近似手法であると言えます。

図4. Constant Liarのワークフロー。この手法は、新たに選択された各点に対して仮の値を挿入することで、後続の選択が先行する選択を完全に無視して行われることを防ぎつつ、貪欲的にバッチを構築します。
なぜConstant Liarはいまも用いられているのか
本稿では、Constant Liarを、バッチ最適化における普遍的に最良の手法としてではなく、代表的な実務的戦略として位置付けています。
それでもなお、現在でも多く利用されている理由は明確です。第一に、理解および説明が比較的容易であることです。第二に、既存の逐次的ワークフローを大きく変更することなく、バッチワークフローへと拡張できる点です。第三に、文献においても、単純で実用的であり、多くの実験パイプラインにおいて十分な性能を示すベースライン手法として繰り返し扱われている点です。
我々の内部評価においても、Constant Liarはすべてのシナリオで常に最良の性能を示すわけではありませんでした。しかしながら、低次元および高次元問題、目的関数の数の違い、離散および連続のパラメータ空間、さらには応答が滑らかな場合と急峻な場合の双方において、安定した最適化挙動を一貫して示しました。このような適用範囲の広さは、実務上の重要な強みの一つです。特定の条件において他の手法が優れていたとしても、多様な条件下においては依然として信頼できる選択肢であり続ける傾向があります。
言い換えれば、Constant Liarが広く使われ続けている理由は、それが常に最良であるからではなく、単純性、計算コスト、性能のバランスにおいて優れた工学的トレードオフを提供するためです。
他の手法が適している場合
Constant Liarはあくまで近似手法です。その挙動は、バッチ構築時に用いられる疑似観測値に依存しており、その選択によってアルゴリズムの振る舞いがより保守的にも、よりアグレッシブにも変化します。
バッチ全体をより直接的に考慮する必要がある場合には、q-EIに基づく手法の方が適している可能性がありますが、その分計算コストは高くなる傾向があります。点の集中を回避することが主目的である場合には、局所ペナルティのような多様性志向の手法が有効です。また、ワークフローが強く非同期的である場合には、サンプリングベースの並列手法が特に適しています。
重要な点は、バッチ最適化は単一の固定された解法ではなく、設計選択の集合であるということです。
まとめ
ベイズ最適化におけるバッチ最適化は、複数の実験を並列に実行できる状況において、各実験ラウンドをより有効に活用するための枠組みです。課題は単に良い候補を見つけることではなく、良い候補の集合を見つけることにあります。Constant Liarは、そのような集合的意思決定を簡潔かつ実用的に近似する方法の古典的な例です。また、バッチ最適化に関する広範な文献は、ワークフローの違いに応じて異なる戦略が選好される理由を示しています。
Appendix
戦略ファミリ | 直感的説明 | 主な強み | トレードオフ |
逐次シミュレーション (例:Constant Liar) | 先に選択された点に仮の観測値があると仮定しながら、順に選択を進める | 説明および実装が容易 | 真の観測結果ではなく近似に依存する |
多様性促進 (例:局所ペナルティ) | 後続の候補が既存の点の近くに集中しないように制約をかける | バッチ内の冗長性を低減できる | 過度に分散し、有望領域から離れる可能性がある |
バッチ同時評価 (例:q-EI) | バッチ全体の価値を同時に評価して最適化する | 真のバッチ意思決定により近い | 計算負荷が高くなる傾向がある |
サンプリングベース並列 (例:並列Thompson Sampling) | 事後分布に基づくランダムな選択を並列で行う | 並列・非同期環境に自然に適合する | 挙動が直感的に理解しにくい場合がある |
参考文献
- Brochu, E., Cora, V. M., & de Freitas, N. (2010). A Tutorial on Bayesian Optimization of Expensive Cost Functions, with Application to Active User Modeling and Hierarchical Reinforcement Learning. arXiv:1012.2599. https://arxiv.org/abs/1012.2599
- Snoek, J., Larochelle, H., & Adams, R. P. (2012). Practical Bayesian Optimization of Machine Learning Algorithms. Advances in Neural Information Processing Systems 25. https://proceedings.neurips.cc/paper/2012/file/05311655a15b75fab86956663e1819cd-Paper.pdf
- Ginsbourger, D., Le Riche, R., & Carraro, L. (2008/2010). Kriging is Well-Suited to Parallelize Optimization / A Multi-points Criterion for Deterministic Parallel Global Optimization based on Gaussian Processes. Introduces Constant Liar and related heuristics for parallel EI-style selection. https://www.cs.ubc.ca/labs/algorithms/EARG/stack/2010_CI_Ginsbourger-ParallelKriging.pdf
- Azimi, J., Fern, A., & Fern, X. (2012). Hybrid Batch Bayesian Optimization. ICML 2012. Discusses Constant Liar as a representative batch heuristic and analyzes simulated sequential batch policies. https://icml.cc/2012/papers/614.pdf
- González, J., Dai, Z., Lawrence, N. D., & Hennig, P. (2016). Batch Bayesian Optimization via Local Penalization. AISTATS 2016. https://proceedings.mlr.press/v51/gonzalez16a.html
- Wang, J., Clark, S. C., Liu, E., & Frazier, P. I. (2020). Parallel Bayesian Global Optimization of Expensive Functions. Operations Research, 68(2), 1-21. Compares q-EI-style optimization with Constant Liar baselines and discusses computational trade-offs. https://pubsonline.informs.org/doi/10.1287/opre.2019.1966
- Kandasamy, K., Krishnamurthy, A., Schneider, J., & Póczos, B. (2018). Parallelised Bayesian Optimisation via Thompson Sampling. AISTATS 2018. https://proceedings.mlr.press/v84/kandasamy18a.html















